
캡스톤디자인에서, 챗봇 질문 시스템 설계를 하면서 구현한 내용을 정리하였다.
1. 챗봇 시스템 설계
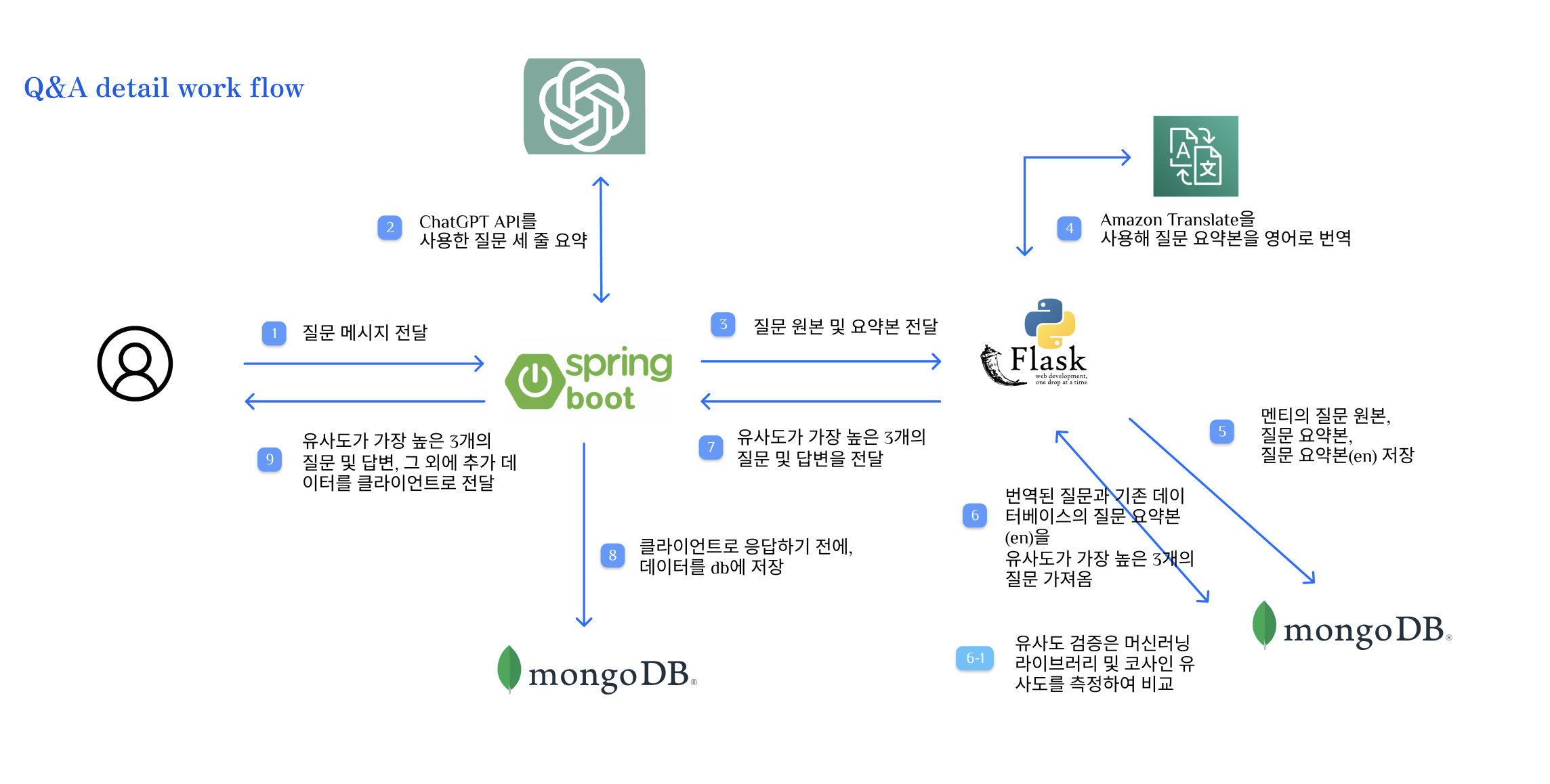
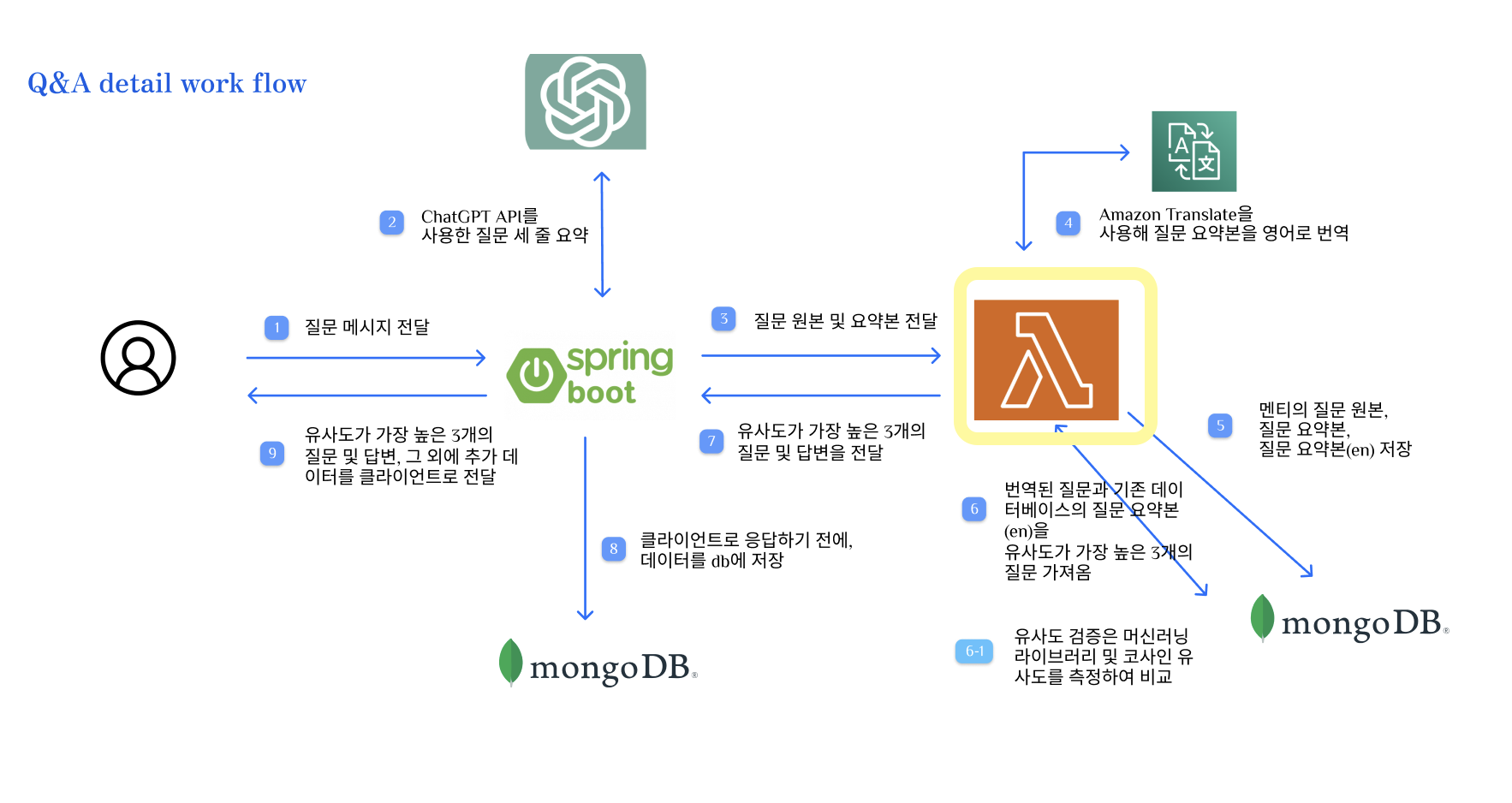
절차를 글로 풀어서 설명하면,
- 사용자(멘티)가 질문을 입력한다.
- Spring Boot에서 질문을 받은 다음, ChatGPT API를 사용하여 사용자의 질문을 세 줄 요약한 메시지를 받는다.
- 멘티 닉네임, 멘토 닉네임, 원본 질문(1번), 세 줄 요약된 질문(2번)을 Flask로 전달한다.
- Flask에서, 먼저 AWS Translate API를 사용하여 세 줄 요약된 질문을 영어로 번역하는 작업을 수행한다.
- 이후 멘티의 질문 원본, 질문 요약본, 질문 요약본(en) 등의 데이터를 MongoDB에 저장한다.
- 번역된 질문(en)과 기존 MongoDB에 저장된 질문 요약본(en)을, Sentence Transformer 머신러닝 라이브러리를 사용하여 유사도 검증을 수행한다.
- MongoDB에서 질문 요약본(en)을 조회할 때, 답변이 null이 아닌 값들만 조회한다.
- 유사도가 가장 높은, 3개의 질문과 그에 대한 답변 그리고 유사도 퍼센테이지를 Spring Boot로 전달한다.
- Spring Boot에서 해당 내용을 MongoDB에 먼저 저장한다
- 이후 클라이언트로 응답을 보낸다.
2. 배포
EC2에 Spring Boot와 Flask를 Dockerfile을 사용해서 각각 배포하였으며, 정상적으로 실행되는 것을 확인하였다.
- Spring Boot는 Port 8080, Flask는 Port 5000
Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY . /app
COPY requirements.txt requirements.txt
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Make port 5000 available to the world outside this container
EXPOSE 5000
# Run Flask app when the container launches
CMD ["python3", "-m", "flask", "run", "--host=0.0.0.0"]
app.py
import boto3 # The AWS SDK for Python
from flask import Flask, request, jsonify
from pymongo import MongoClient
from sentence_transformers import SentenceTransformer, util
import config
app = Flask(__name__)
# Declare a constant variable
TARGET_LANGUAGE_CODE = 'en'
SOURCE_LANGUAGE_CODE = 'ko'
# 유사도 기준 점수
SIMILARITY_CRITERION_PERCENT = 10
# Configure AWS Translate client
translate = boto3.client(service_name='translate',
aws_access_key_id=config.AWS_ACCESS_KEY_ID,
aws_secret_access_key=config.AWS_SECRET_ACCESS_KEY,
region_name=config.AWS_SEOUL_REGION)
def get_mongo_client():
username = config.MONGODB_USERNAME
password = config.MONGODB_PASSWORD
host = config.MONGODB_HOST
port = config.MONGODB_PORT
# Create a MongoDB connection URI
mongo_uri = f"mongodb://{username}:{password}@{host}:{port}/"
# Create the MongoDB client and return it
return MongoClient(mongo_uri)
def cosine_similarity_to_percent_general(cosine_similarity):
normalized_value = (cosine_similarity + 1) / 2
return normalized_value * 100
@app.route('/api/chat/flask', methods=['POST'])
def message_from_spring_boot():
""" Declare variables """
mentor_nickname = None
mentee_nickname = None
question_origin = None
question_summary = None # 원본 질문 세 줄 요약본
try:
""" Get data from Spring Boot Server """
data = request.get_json()
mentor_nickname = data['mentor_nickname']
mentee_nickname = data['mentee_nickname']
question_origin = data['question_origin']
question_summary = data['question_summary']
except Exception as e:
return jsonify({'error': str(e)}), 500
""" 받아온 데이터 중, 세 줄 요약된 질문을 AWS Translate API를 통해 영어로 번역 """
translation_response = translate.translate_text(Text=question_summary, SourceLanguageCode=SOURCE_LANGUAGE_CODE,
TargetLanguageCode=TARGET_LANGUAGE_CODE)
""" Extract the translated text from the response """
translated_summary_text_en = translation_response['TranslatedText']
""" Connect MongoDB """
mongo_client = get_mongo_client()
menjil_db = mongo_client['menjil']
qa_list_collection = menjil_db['qa_list']
"""qa_list collection에 접근해서, Spring Boot에서 받아온 정보(멘토 닉네임, 멘티 닉네임, 원본 질문, 세 줄 요약된 질문)와 영어 번역본을 먼저 저장"""
document = {
# 마지막에 붙는 '\n' 제거
'mentee_nickname': mentee_nickname,
'mentor_nickname': mentor_nickname,
'question_origin': question_origin[:-1] if question_origin.endswith('\n') else question_origin,
'question_summary': question_summary[:-1] if question_summary.endswith('\n') else question_summary,
'question_summary_en': translated_summary_text_en[:-1] if translated_summary_text_en.endswith('\n')
else translated_summary_text_en,
'answer': None
}
insert = qa_list_collection.insert_one(document) # save a document
""" 멘토가 답변한 내역이 있는 문답 데이터를 모두 불러온다 """
filter_ = {
'mentor_nickname': mentor_nickname,
'answer': {'$exists': True, '$ne': None}
}
projection_ = {
'mentee_nickname': False,
'mentor_nickname': False,
'question_origin': False
}
# Retrieve the documents and store them in the data(list)
data = list(qa_list_collection.find(filter_, projection_))
# print('data: ', data)
""" 문장 유사도 검증 """
""" 1. 유사도 검사"""
question_summary_en_list = [doc['question_summary_en'] for doc in data]
# for idx, qe in enumerate(question_summary_en_list):
# print(f'질문{idx + 1}: {qe}')
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
query_embedding = model.encode(translated_summary_text_en, convert_to_tensor=True)
passage_embedding = model.encode(question_summary_en_list, convert_to_tensor=True)
# Use Cosine Similarity
cos_score = util.cos_sim(query_embedding, passage_embedding)
# Normalize
cos_score_percent = cosine_similarity_to_percent_general(cos_score)
cos_score_percent_list = cos_score_percent.tolist()[0]
""" 2. 계산된 데이터 중 유사도 상위 3개 데이터 추출 """
similarity_list = [{'similarity_percent': 0}, {'similarity_percent': 0}, {'similarity_percent': 0}]
for doc, score in zip(data, cos_score_percent_list):
doc['similarity_percent'] = score
sim_list = [d['similarity_percent'] for d in similarity_list]
if score > min(sim_list):
idx_min = sim_list.index(min(sim_list))
similarity_list[idx_min] = doc
""" 3. 유사도 점수가 기준 점수(SIMILARITY_CRITERION_POINT) 이하인 데이터 삭제 """
# result_similarity_list = []
# for doc in similarity_list:
# if doc['similarity_percent'] > SIMILARITY_CRITERION_PERCENT:
# result_similarity_list.append(doc)
# 유사도 상위 3개의 데이터 출력
# print(result_similarity_list)
""" 결과가 3개 미만일 경우, 빈 리스트를 Spring Boot로 리턴"""
if len(similarity_list) < 3:
return []
""" 요약된 질문과 답변을 DTO로 담아서 리턴(Spring Boot로 전달) """
# List of DTOs
data_list = []
for i in similarity_list:
dict_ = dict()
dict_['question_summary'] = i.get('question_summary')
dict_['answer'] = i.get('answer')
dict_['similarity_percent'] = round(i.get('similarity_percent'), 2) # Rounded to 2 decimal places
data_list.append(dict_)
print(dict_)
# Sort the data_list by 'similarity_percent' in descending order
data_list = sorted(data_list, key=lambda x: x['similarity_percent'], reverse=True)
return data_list
if __name__ == '__main__':
app.run(debug=True)
requirements.txt
boto3~=1.28.16
Flask~=2.3.2
pymongo~=4.4.1
sentence-transformers~=2.2.2
3. 문제 사항
- EC2 리소스 낭비
- 메인으로 개발된 Spring Boot 서버와 달리, Flask 서버의 경우 위에서 챗봇 서비스 중 사용자가 질문을 할 때만 사용이 되며, 그 외에는 사용되지 않는 서비스이다. 사용하지 않을 때도 지속해서 실행되고 항상 사용 가능한 서버 또는 서버 블록을 구입하는 것은 리소스 낭비일 수 있다.
- 따라서, 비록 챗봇이 메인 기능이지만, Flask 서버를 5000 포트로 24시간 내내 EC2 인스턴스에 실행시키는 것은 리소스 낭비를 유발한다.
- Docker image 용량
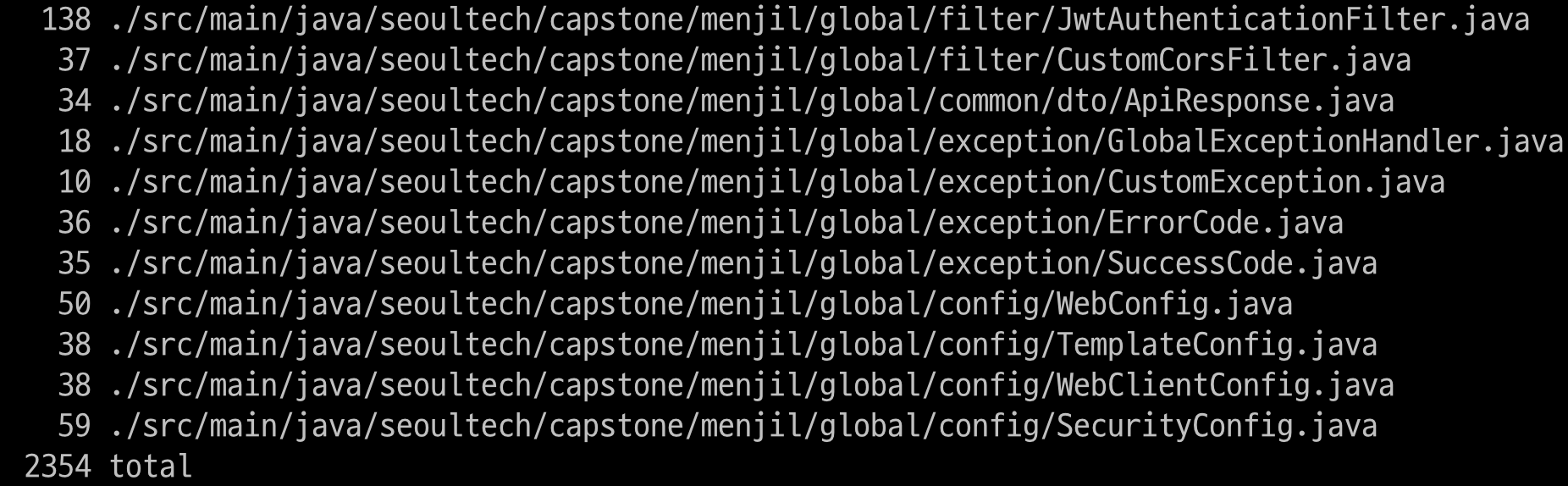
- 아래는 `docker images` 명령을 통해 나온 결과인데, flask 프로젝트의 이미지 용량이 Spring Boot에 비해 훨씬 큰 것을 알 수 있다.
- 코드의 line 개수는 아래와 같이, Spring Boot 프로젝트(테스트 코드 제외)가 flask 프로젝트에 비해 약 10배 이상이 작성되어 있음에도 불구하고, flask 프로젝트의 이미지 용량이 Spring Boot에 비해 훨씬 큰 것을 알 수 있다.
- 이는 EC2의 Volume을 추가해야 하는 상황을 유발할 수 있다.


4. 컨테이너 이미지를 사용하여 AWS Lambda 배포
https://gallery.ecr.aws/lambda/python
- 따라서, 서버리스 컴퓨팅 서비스인 AWS Lambda를 사용하기로 하였다.
- 또한, 2020년부터 AWS Lambda는 컨테이너 이미지로 함수를 패키징하고 배포할 수 있는 기능을 제공하므로, AWS ECR과 연동해서 사용하면 버전 관리가 가능하다.
4-1. 코드 수정
Dockerfile
AWS] 컨테이너 이미지로 Python Lambda 함수 배포
위 링크를 참고하여 수정하였다.
주의] 마지막 줄에서, app.py에 lambda_handler 라는 명칭의 함수가 존재해야 한다.
# Use public ECR provided Python Runtime for AWS Lambda
FROM public.ecr.aws/lambda/python:3.9
# Set the working directory
WORKDIR ${LAMBDA_TASK_ROOT}
# Copy requirements.txt
COPY requirements.txt .
# Install the specified packages
RUN pip install -r requirements.txt
# Copy function code
COPY app.py .
COPY config.py .
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "app.lambda_handler" ]
app.py
이제 Flask 서버를 사용할 것이 아니므로, Flask 코드를 AWS Lambda 형식으로 수정하였다.
import boto3 # The AWS SDK for Python
from pymongo import MongoClient
from sentence_transformers import SentenceTransformer, util
import config
import os
# Declare a constant variable
TARGET_LANGUAGE_CODE = 'en'
SOURCE_LANGUAGE_CODE = 'ko'
# Similarity Criterion Percent
SIMILARITY_CRITERION_PERCENT = 10
def get_mongo_client():
username = config.MONGODB_USERNAME
password = config.MONGODB_PASSWORD
host = config.MONGODB_HOST
port = config.MONGODB_PORT
# Create a MongoDB connection URI
mongo_uri = f'mongodb://{username}:{password}@{host}:{port}/'
# Create the MongoDB client and return it
return MongoClient(mongo_uri)
def cosine_similarity_to_percent_general(cosine_similarity):
normalized_value = (cosine_similarity + 1) / 2
return normalized_value * 100
def lambda_handler(event, context):
os.environ['TRANSFORMERS_CACHE'] = "/tmp"
# Configure AWS Translate client
translate = boto3.client(service_name='translate',
aws_access_key_id=config.AWS_ACCESS_KEY_ID,
aws_secret_access_key=config.AWS_SECRET_ACCESS_KEY,
region_name=config.AWS_SEOUL_REGION)
mentor_nickname = event['mentor_nickname']
mentee_nickname = event['mentee_nickname']
question_origin = event['question_origin']
question_summary = event['question_summary']
""" 받아온 데이터 중, 세 줄 요약된 질문을 AWS Translate API를 통해 영어로 번역 """
translation_response = translate.translate_text(Text=question_summary, SourceLanguageCode=SOURCE_LANGUAGE_CODE,
TargetLanguageCode=TARGET_LANGUAGE_CODE)
""" Extract the translated text from the response """
translated_summary_text_en = translation_response['TranslatedText']
""" Connect MongoDB """
mongo_client = get_mongo_client()
menjil_db = mongo_client['menjil']
qa_list_collection = menjil_db['qa_list']
"""qa_list collection에 접근해서, Spring Boot에서 받아온 정보(멘토 닉네임, 멘티 닉네임, 원본 질문, 세 줄 요약된 질문)와 영어 번역본을 먼저 저장"""
document = {
# 마지막에 붙는 '\n' 제거
'mentee_nickname': mentee_nickname,
'mentor_nickname': mentor_nickname,
'question_origin': question_origin[:-1] if question_origin.endswith('\n') else question_origin,
'question_summary': question_summary[:-1] if question_summary.endswith('\n') else question_summary,
'question_summary_en': translated_summary_text_en[:-1] if translated_summary_text_en.endswith('\n')
else translated_summary_text_en,
'answer': None
}
insert = qa_list_collection.insert_one(document) # save a document
""" 멘토가 답변한 내역이 있는 문답 데이터를 모두 불러온다 """
filter_ = {
'mentor_nickname': mentor_nickname,
'answer': {'$exists': True, '$ne': None}
}
projection_ = {
'mentee_nickname': False,
'mentor_nickname': False,
'question_origin': False
}
# Retrieve the documents and store them in the data(list)
data = list(qa_list_collection.find(filter_, projection_))
print('data: ', data)
""" 문장 유사도 검증 """
""" 1. 유사도 검사"""
question_summary_en_list = [doc['question_summary_en'] for doc in data]
# for idx, qe in enumerate(question_summary_en_list):
# print(f'질문{idx + 1}: {qe}')
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2', cache_folder='/tmp')
query_embedding = model.encode(translated_summary_text_en, convert_to_tensor=True)
passage_embedding = model.encode(question_summary_en_list, convert_to_tensor=True)
# Use Cosine Similarity
cos_score = util.cos_sim(query_embedding, passage_embedding)
# Normalize
cos_score_percent = cosine_similarity_to_percent_general(cos_score)
cos_score_percent_list = cos_score_percent.tolist()[0]
""" 2. 계산된 데이터 중 유사도 상위 3개 데이터 추출 """
similarity_list = [{'similarity_percent': 0}, {'similarity_percent': 0}, {'similarity_percent': 0}]
for doc, score in zip(data, cos_score_percent_list):
doc['similarity_percent'] = score
sim_list = [d['similarity_percent'] for d in similarity_list]
if score > min(sim_list):
idx_min = sim_list.index(min(sim_list))
similarity_list[idx_min] = doc
""" 3. 유사도 점수가 기준 점수(SIMILARITY_CRITERION_POINT) 이하인 데이터 삭제 """
# result_similarity_list = []
# for doc in similarity_list:
# if doc['similarity_percent'] > SIMILARITY_CRITERION_PERCENT:
# result_similarity_list.append(doc)
# 유사도 상위 3개의 데이터 출력
# print(result_similarity_list)
""" 결과가 3개 미만일 경우, 빈 리스트를 Spring Boot로 리턴"""
if len(similarity_list) < 3:
return []
""" 요약된 질문과 답변을 DTO로 담아서 리턴(Spring Boot로 전달) """
# List of DTOs
data_list = []
for i in similarity_list:
dict_ = dict()
dict_['question_summary'] = i.get('question_summary')
dict_['answer'] = i.get('answer')
dict_['similarity_percent'] = round(i.get('similarity_percent'), 2) # Rounded to 2 decimal places
data_list.append(dict_)
print(dict_)
# Sort the data_list by 'similarity_percent' in descending order
data_list = sorted(data_list, key=lambda x: x['similarity_percent'], reverse=True)
return data_list
requirements.txt
주의] sentence-transformers==2.2.2만 넣으면, Lambda에서 오류가 발생한다.
StackoverFlow에서 검색을 해보니, "AWS Lambda currently doesn't support GPU-based operations directly, so any library or framework that requires direct GPU support (like some parts of PyTorch when it tries to load CUDA libraries) might fail." 라고 말해서,
CPU Only version of pytorch를 설치하기 위해 https://download.pytorch. ... 를 추가해야 한다.
pymongo~=4.4.1
numpy~=1.25.2
https://download.pytorch.org/whl/cpu/torch-1.11.0%2Bcpu-cp39-cp39-linux_x86_64.whl
sentence-transformers==2.2.2
그 외 오류 사항: 주로 AWS Lambda에서 ECR 이미지 실행 시 발생하였으며, 모두 Sentence Transformer 라이브러리 관련한 것이었다.
CloudWatch 로그에서 확인된, 오류 내용
1. There was a problem when trying to write in your cache folder (/home/sbx_user1051/.cache/huggingface/hub). You should set the environment variable TRANSFORMERS_CACHE to a writable directory.

Stackoverflow] How to change huggingface transformers default cache directory
해결] 아래 코드를 추가한다.
주의] 이때, 경로를 내 마음대로 지정하면 안 된다. AWS Lambda에서는 /tmp 영역에 임시 파일 시스템을 제공하며, 고정 크기는 512MB이다. 따라서, /tmp 영역 안으로 경로를 지정해야 한다!
( /tmp 영역은 실행 환경의 수명 동안 보존되며, 호출 사이의 데이터에 대한 임시 캐시를 제공한다. 새 실행 환경이 생성될 때마다 이 영역은 삭제된다. )
import os
os.environ["TRANSFORMERS_CACHE"] = "/tmp"
2. [ERROR] OSError: [Errno 30] Read-only file system: '/home/sbx_user1051' Traceback (most recent call last): File "/var/task/app.py", line 91, in lambda_handler model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
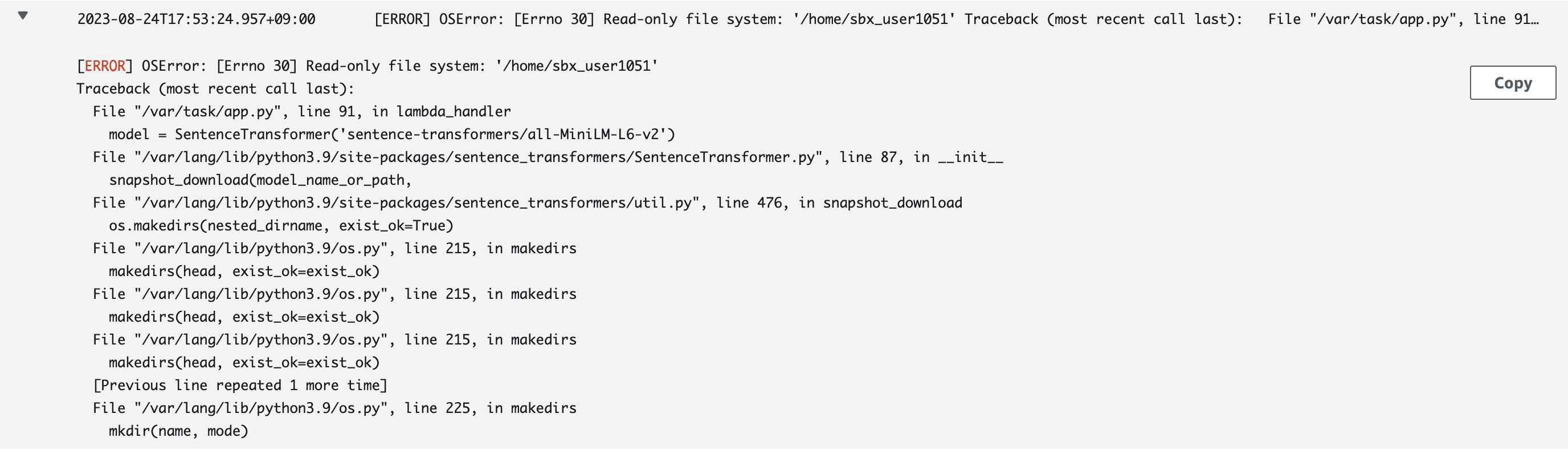
해결] cache_folder를 코드에 추가하였음.
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2', cache_folder='/tmp')
3. [ERROR] Runtime.UserCodeSyntaxError: Syntax error in module 'app': invalid syntax (config.py, line 3)

AWS Lambda Runtime.UserCodeSyntaxError: Syntax error in module 'salesAnalysisReport': invalid syntax
해결] Boto3에서는, single quote를 사용해야 한다. double quote를 사용해서 오류가 난 것이었음
4-2. IAM user 생성
4-3에서, GitHub Action 사용 시에 AWS IAM user의 정보가 필요하므로, IAM user를 생성하였다.
- AmazonEC2ContainerRegistryFullAccess
생성 이후, IAM user > Create Access Key 를 통해, Access Key, Secret Access Key 정보가 담긴 csv 파일을 저장한다.
4-3. AWS ECR 생성 및, GitHub Action을 사용한 CD 구성
주의] ECR 생성 시, 반드시 Private Repository를 생성해야 한다!!
Public Repository로 생성했는데, 이후 AWS Lambda에서 리포지토리가 검색이 되지 않아서 한참 헤맸다..
생성 이후 우측 상단에 "View push commands" 를 누르면 아래 사진과 같은 command를 볼 수 있는데,
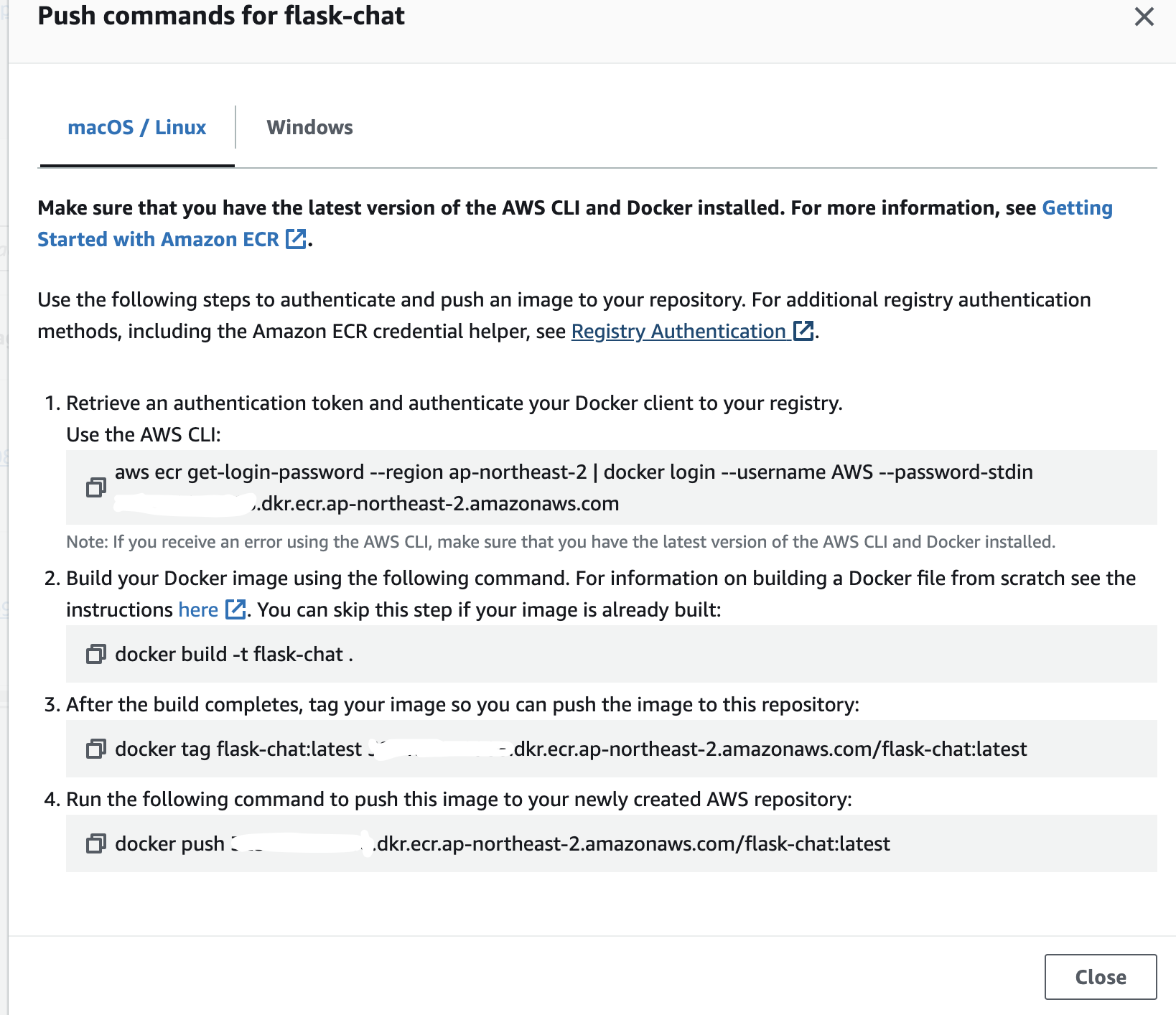
- AWS CLI 설치 필요
- 코드에서 변경 사항이 발생할 때 마다 매번 명령어 입력
위 두 가지 번거로운 사항이 존재해서, GitHub Action으로 Deploy를 실행하기로 하였다.
app.yml
ECR_REPOSITORY의 경우 Repository 명칭을 작성한다. e.g) lambda-test
name: Deploy image To AWS ECR
on:
push:
branches: [ "main" ]
permissions:
contents: read
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-2
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
with:
mask-password: 'true'
- name: Build, tag, and push docker image to Amazon ECR
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
ECR_REPOSITORY: ${{ secrets.FLASK_ECR_REPO }}
IMAGE_TAG: ${{ github.sha }}
run: |
touch ./config.py
echo "${{secrets.APPLICATION_CONFIG}}" > ./config.py
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
실행 결과
위의 app.yml 코드가 정상적으로 실행되면, ECR Repository에, 아래와 같이 image가 등록이 된다.
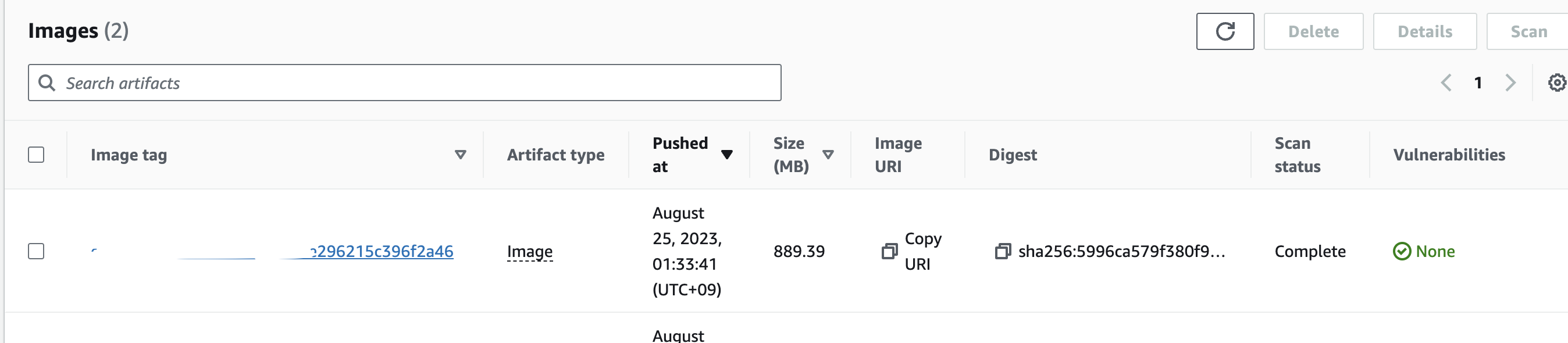
4-4. AWS Lambda 함수 생성
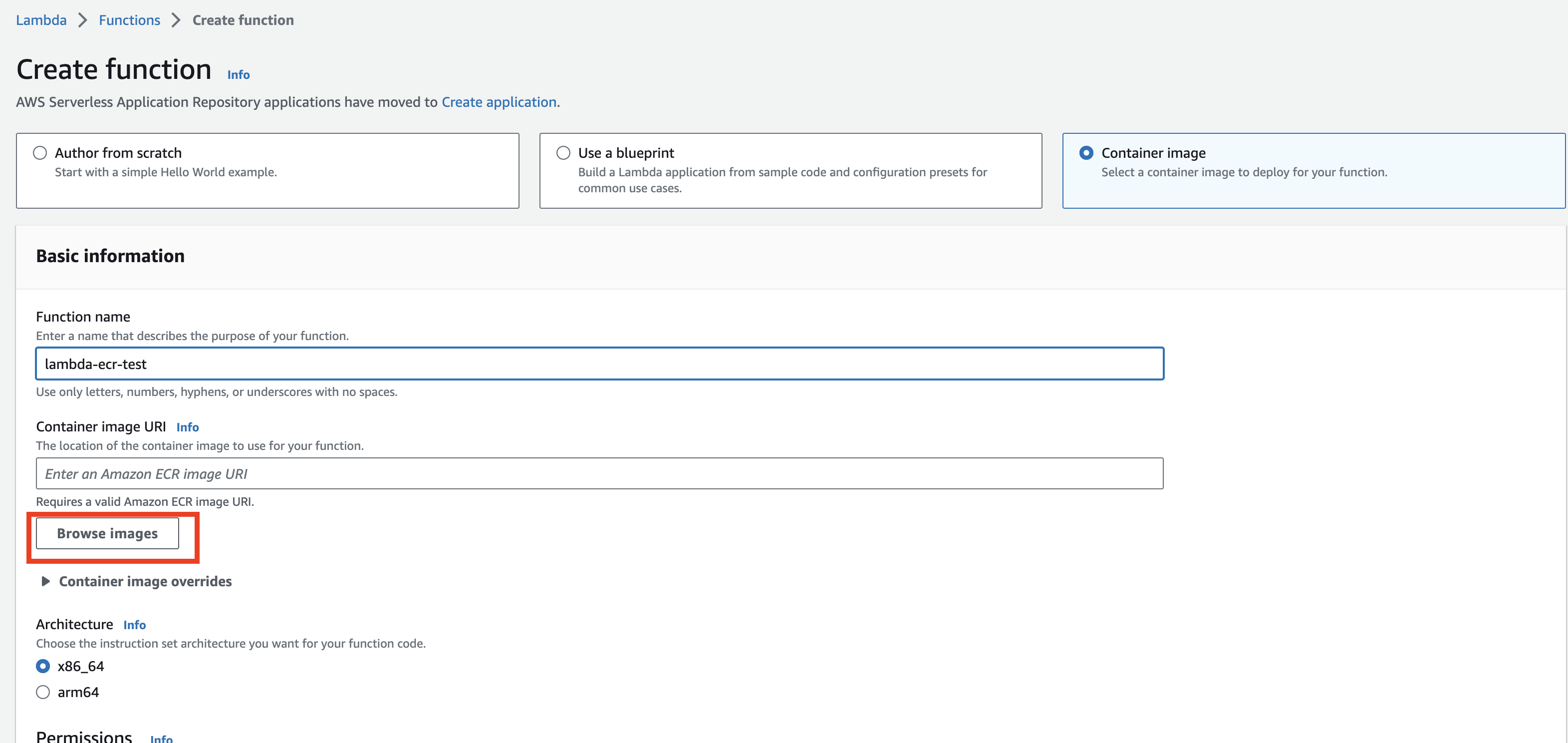
Browse images를 클릭하면, 4-3에서 생성한 private repository를 확인할 수 있다.
public repository는 확인 불가능.
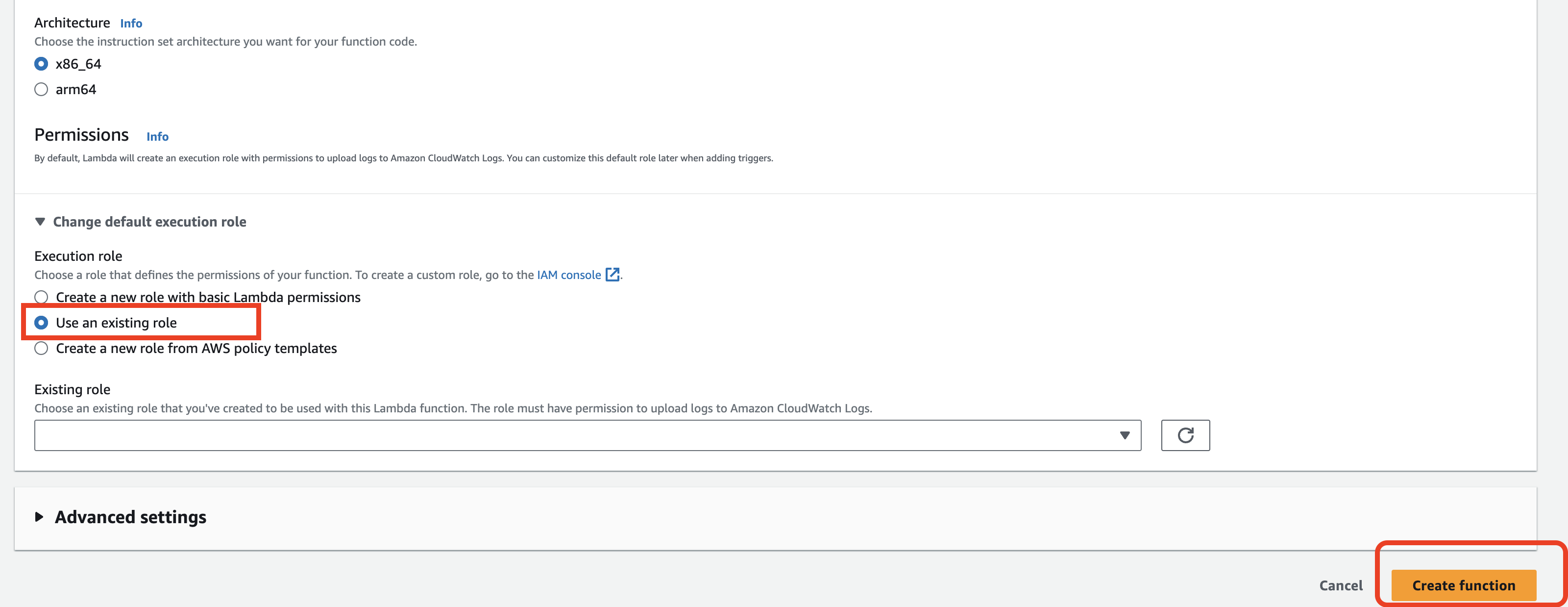
다음으로, 아래에서 사용하기 위한 IAM Roles을 생성한다.
설정한 권한 역시 사진 참고

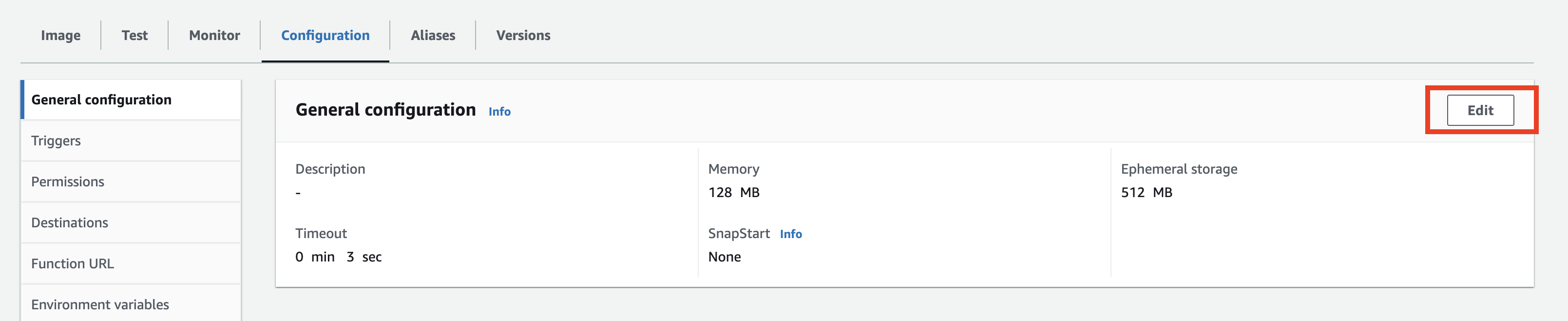
Lambda 설정
정상적으로 생성되었다면, 다음 동작들을 수행한다.
1. Memory -> 512 MB, Timeout -> 1m 30s 로 변경
2. Json 데이터를 내 요청 형식에 맞도록 작성한뒤, Test 수행
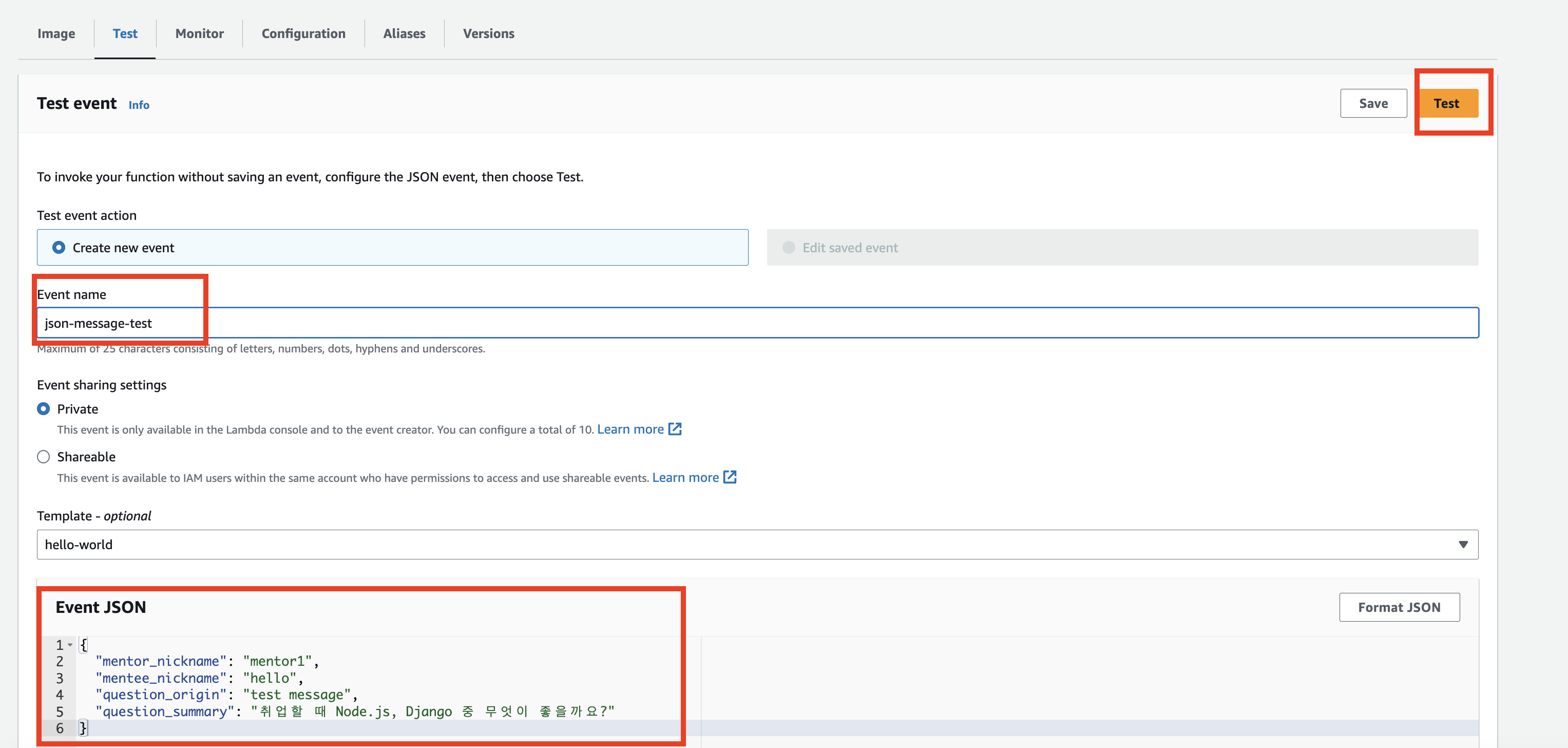
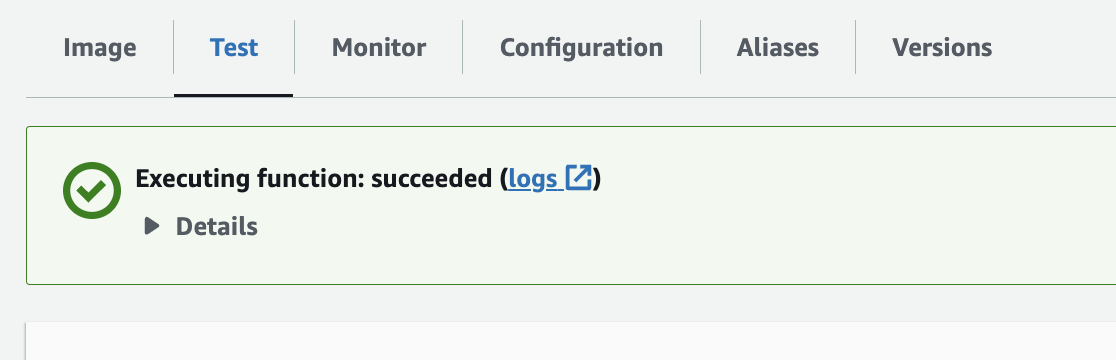
3. 성공 시 아래와 같이 succeeded 메시지가 뜬다. 만약 실패하였다면, logs로 가서 원인을 확인 후 고친다.
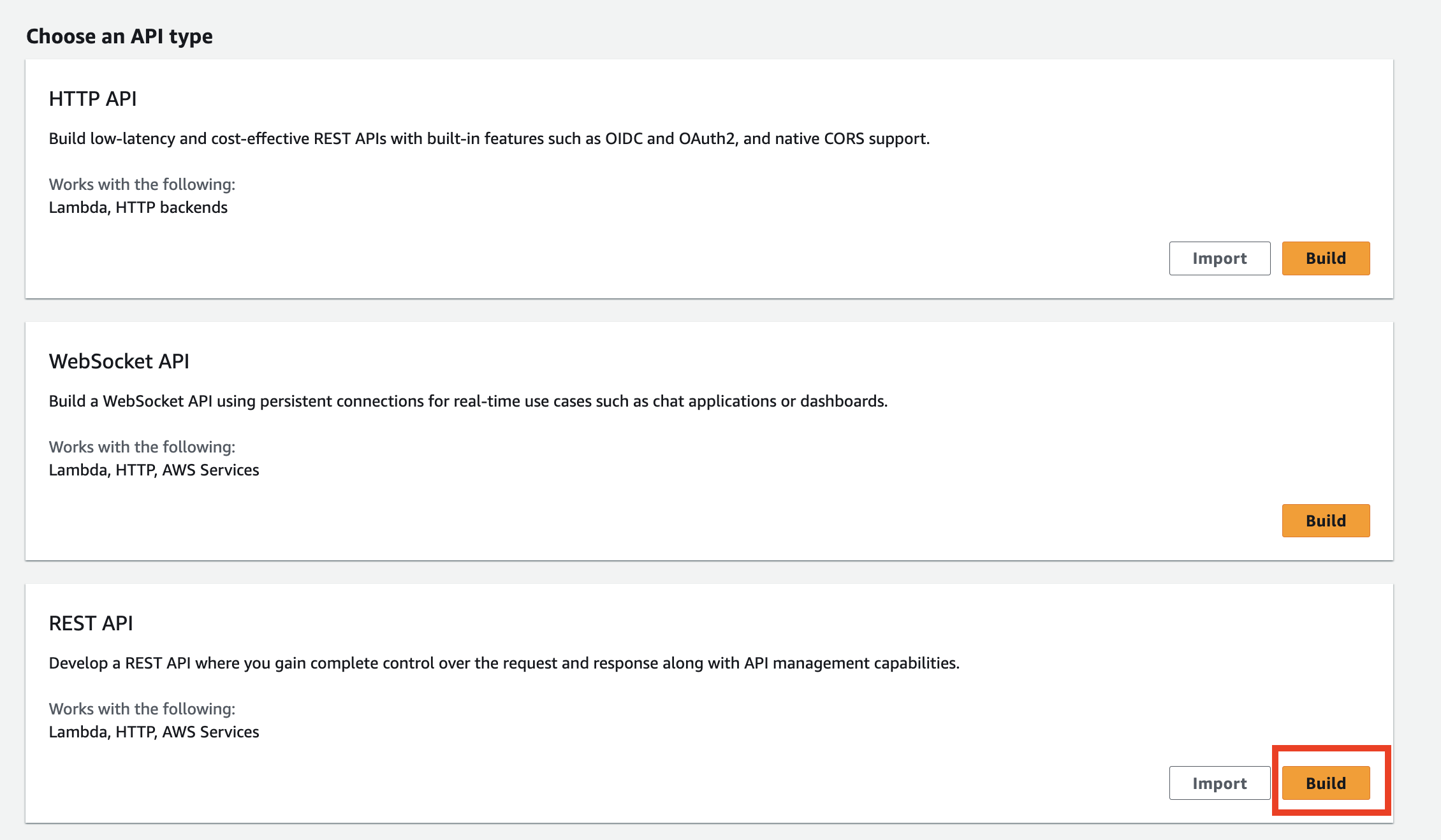
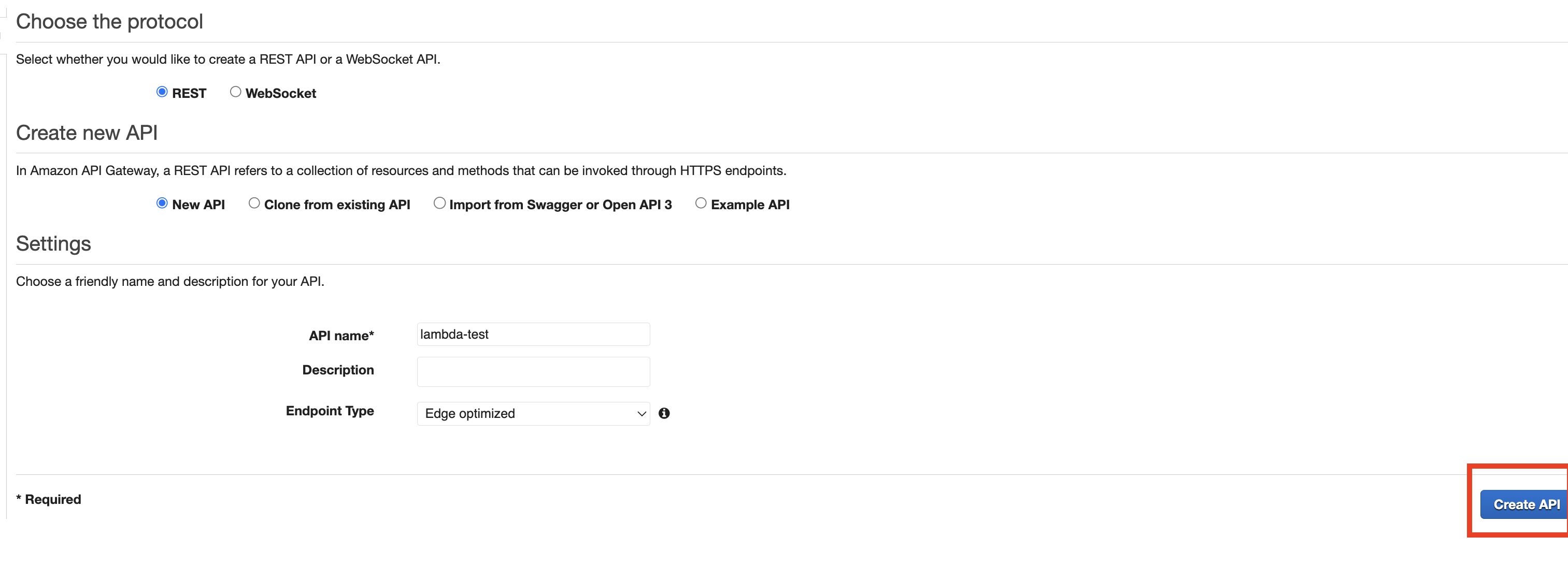
4-5. API Gateway 생성 및 Lambda와 연결
1. API Gateway 생성
2. 리소스를 생성하고, 메서드를 생성한다. 나는 JSON 데이터를 body에 담아 전달하므로, POST 요청을 사용한다.
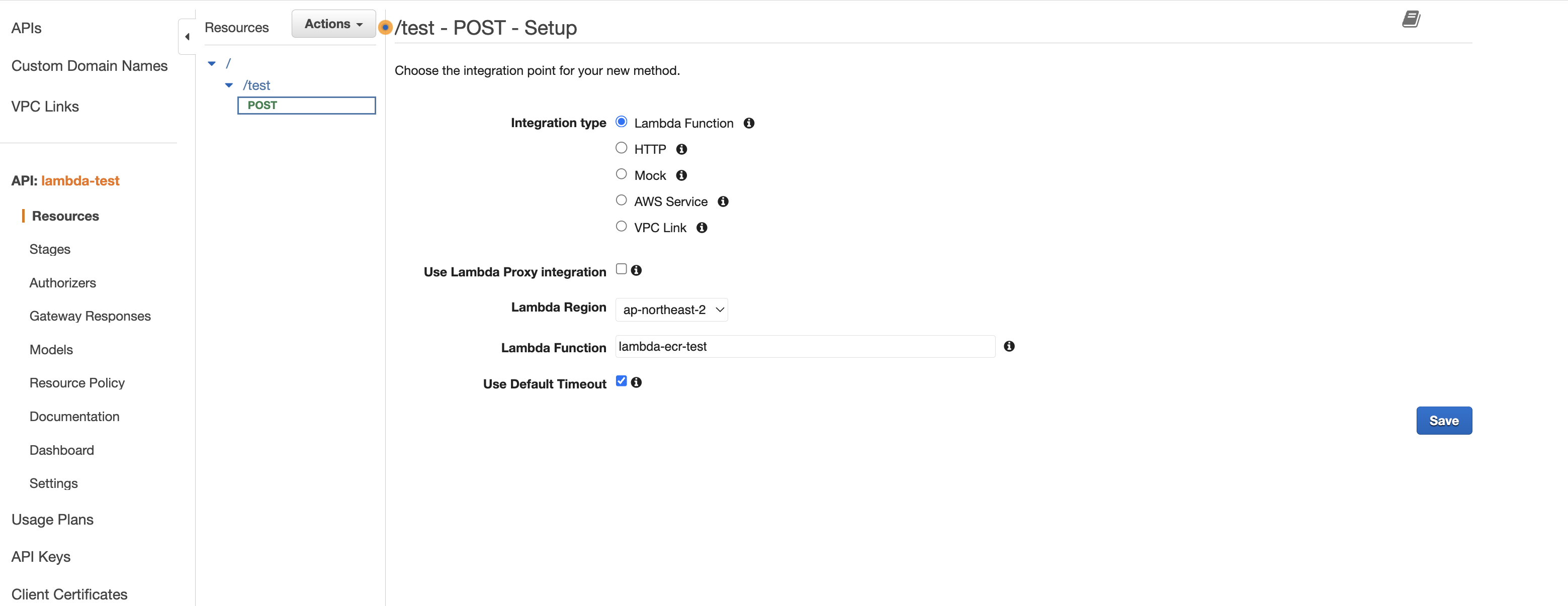
3. 정상적으로 동작하는지 test를 수행한다.
Request Body에 json 데이터를 입력하였다.
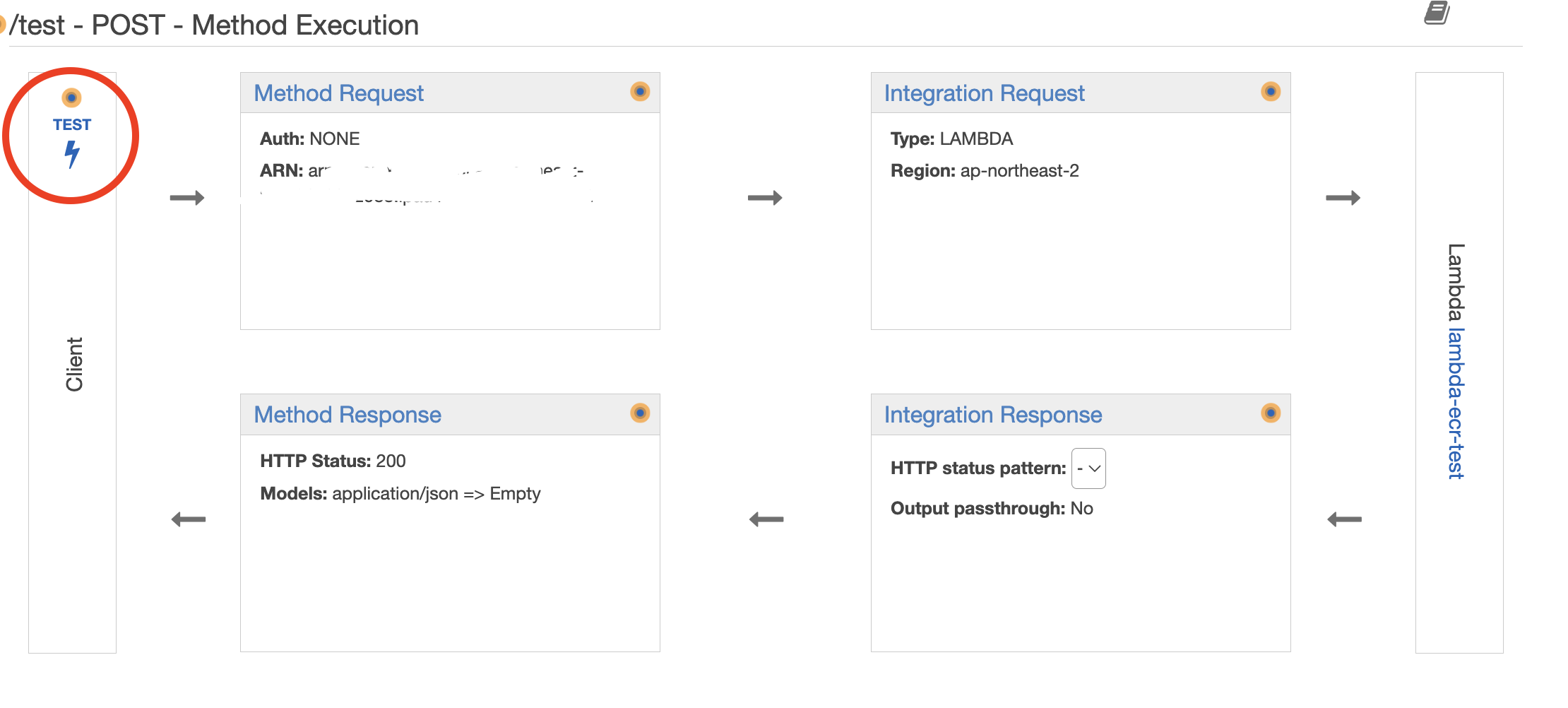
4. 위에서 테스트가 성공하였다면, Deploy API를 눌러 배포한다.
stage name은 prod, dev 등 마음대로 작성한다.
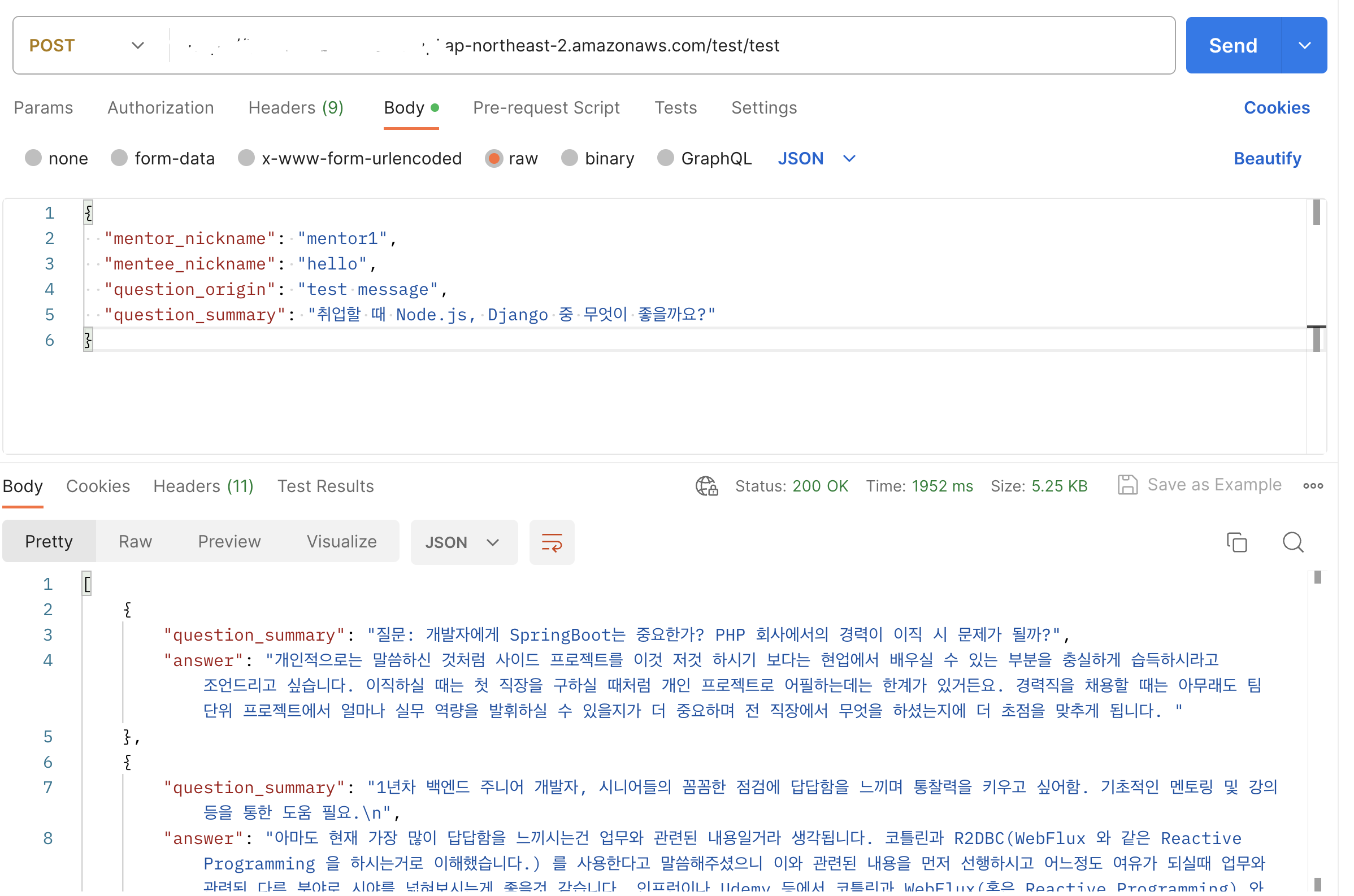
5. Invoke URL + 내가 작성한 Resources 경로를 추가하여, Postman으로 테스트 수행
정상적으로 응답이 오는 것을 확인할 수 있다.
5. 결론
- AWS ECR + Lambda + Api gateway를 사용하여, 기존 EC2 인스턴스의 부하를 줄일 수 있었다고 생각한다.
- AWS Lambda는 도커 이미지의 경우 10GB 용량 제한이 있으므로 추후 여러 머신러닝 라이브러리를 사용할 일이 있다면, AWS Sagemaker의 사용을 고려해볼 것이다.
- 현재 하나의 AWS Lambda에서 AWS Translate API, MonogoDB에 document 저장, 유사도 검증, 결과 응답 이 4가지의 기능을 수행하고 있는데, 아래와 같이 Lambda를 여러 개를 사용하여 기능을 분리한다면, 조금 더 안정적인 서비스가 되지 않을까 생각한다.
- AWS Translate API
- MonogoDB에 document 저장
- 유사도 검증 및 결과 응답
- 혹은 AWS Translate API, MonogoDB에 document 저장하는 두 절차는 Spring Boot에서 처리하고, 유사도 검증 및 결과 응답만 AWS Lambda에서 처리하도록 한다.
6. 더 나아가기
1. AWS에서, EC2 인스턴스의 상태를 확인이 가능하다면, Flask 서버를 띄웠을 때와 안 띄웠을 때 얼마나 차이가 나는지 확인이 가능한지.
2. ecr에 이미지 업로드 이후, 람다에서 직접 deploy를 수동으로 수행하고 있는데, 람다에 deploy 및 test도 github action에서 자동화할 수 있을까
'멘질멘질] 2023 졸업 프로젝트' 카테고리의 다른 글
| Spring Boot] API 문서의 신뢰도를 높이기 위한 Spring Rest Docs 도입 (0) | 2024.01.22 |
|---|---|
| Spring Boot] STOMP 프로토콜 (0) | 2023.09.01 |
| Junit5] @CreatedDate NullPointer Exception (0) | 2023.07.22 |
| Ubuntu] Docker 용량 줄이기 (0) | 2023.06.25 |
| Ubuntu] Next.js Dockerfile 경량화(Optimize) (0) | 2023.06.22 |
캡스톤디자인에서, 챗봇 질문 시스템 설계를 하면서 구현한 내용을 정리하였다.
1. 챗봇 시스템 설계
절차를 글로 풀어서 설명하면,
- 사용자(멘티)가 질문을 입력한다.
- Spring Boot에서 질문을 받은 다음, ChatGPT API를 사용하여 사용자의 질문을 세 줄 요약한 메시지를 받는다.
- 멘티 닉네임, 멘토 닉네임, 원본 질문(1번), 세 줄 요약된 질문(2번)을 Flask로 전달한다.
- Flask에서, 먼저 AWS Translate API를 사용하여 세 줄 요약된 질문을 영어로 번역하는 작업을 수행한다.
- 이후 멘티의 질문 원본, 질문 요약본, 질문 요약본(en) 등의 데이터를 MongoDB에 저장한다.
- 번역된 질문(en)과 기존 MongoDB에 저장된 질문 요약본(en)을, Sentence Transformer 머신러닝 라이브러리를 사용하여 유사도 검증을 수행한다.
- MongoDB에서 질문 요약본(en)을 조회할 때, 답변이 null이 아닌 값들만 조회한다.
- 유사도가 가장 높은, 3개의 질문과 그에 대한 답변 그리고 유사도 퍼센테이지를 Spring Boot로 전달한다.
- Spring Boot에서 해당 내용을 MongoDB에 먼저 저장한다
- 이후 클라이언트로 응답을 보낸다.
2. 배포
EC2에 Spring Boot와 Flask를 Dockerfile을 사용해서 각각 배포하였으며, 정상적으로 실행되는 것을 확인하였다.
- Spring Boot는 Port 8080, Flask는 Port 5000
Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY . /app
COPY requirements.txt requirements.txt
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Make port 5000 available to the world outside this container
EXPOSE 5000
# Run Flask app when the container launches
CMD ["python3", "-m", "flask", "run", "--host=0.0.0.0"]
app.py
import boto3 # The AWS SDK for Python
from flask import Flask, request, jsonify
from pymongo import MongoClient
from sentence_transformers import SentenceTransformer, util
import config
app = Flask(__name__)
# Declare a constant variable
TARGET_LANGUAGE_CODE = 'en'
SOURCE_LANGUAGE_CODE = 'ko'
# 유사도 기준 점수
SIMILARITY_CRITERION_PERCENT = 10
# Configure AWS Translate client
translate = boto3.client(service_name='translate',
aws_access_key_id=config.AWS_ACCESS_KEY_ID,
aws_secret_access_key=config.AWS_SECRET_ACCESS_KEY,
region_name=config.AWS_SEOUL_REGION)
def get_mongo_client():
username = config.MONGODB_USERNAME
password = config.MONGODB_PASSWORD
host = config.MONGODB_HOST
port = config.MONGODB_PORT
# Create a MongoDB connection URI
mongo_uri = f"mongodb://{username}:{password}@{host}:{port}/"
# Create the MongoDB client and return it
return MongoClient(mongo_uri)
def cosine_similarity_to_percent_general(cosine_similarity):
normalized_value = (cosine_similarity + 1) / 2
return normalized_value * 100
@app.route('/api/chat/flask', methods=['POST'])
def message_from_spring_boot():
""" Declare variables """
mentor_nickname = None
mentee_nickname = None
question_origin = None
question_summary = None # 원본 질문 세 줄 요약본
try:
""" Get data from Spring Boot Server """
data = request.get_json()
mentor_nickname = data['mentor_nickname']
mentee_nickname = data['mentee_nickname']
question_origin = data['question_origin']
question_summary = data['question_summary']
except Exception as e:
return jsonify({'error': str(e)}), 500
""" 받아온 데이터 중, 세 줄 요약된 질문을 AWS Translate API를 통해 영어로 번역 """
translation_response = translate.translate_text(Text=question_summary, SourceLanguageCode=SOURCE_LANGUAGE_CODE,
TargetLanguageCode=TARGET_LANGUAGE_CODE)
""" Extract the translated text from the response """
translated_summary_text_en = translation_response['TranslatedText']
""" Connect MongoDB """
mongo_client = get_mongo_client()
menjil_db = mongo_client['menjil']
qa_list_collection = menjil_db['qa_list']
"""qa_list collection에 접근해서, Spring Boot에서 받아온 정보(멘토 닉네임, 멘티 닉네임, 원본 질문, 세 줄 요약된 질문)와 영어 번역본을 먼저 저장"""
document = {
# 마지막에 붙는 '\n' 제거
'mentee_nickname': mentee_nickname,
'mentor_nickname': mentor_nickname,
'question_origin': question_origin[:-1] if question_origin.endswith('\n') else question_origin,
'question_summary': question_summary[:-1] if question_summary.endswith('\n') else question_summary,
'question_summary_en': translated_summary_text_en[:-1] if translated_summary_text_en.endswith('\n')
else translated_summary_text_en,
'answer': None
}
insert = qa_list_collection.insert_one(document) # save a document
""" 멘토가 답변한 내역이 있는 문답 데이터를 모두 불러온다 """
filter_ = {
'mentor_nickname': mentor_nickname,
'answer': {'$exists': True, '$ne': None}
}
projection_ = {
'mentee_nickname': False,
'mentor_nickname': False,
'question_origin': False
}
# Retrieve the documents and store them in the data(list)
data = list(qa_list_collection.find(filter_, projection_))
# print('data: ', data)
""" 문장 유사도 검증 """
""" 1. 유사도 검사"""
question_summary_en_list = [doc['question_summary_en'] for doc in data]
# for idx, qe in enumerate(question_summary_en_list):
# print(f'질문{idx + 1}: {qe}')
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
query_embedding = model.encode(translated_summary_text_en, convert_to_tensor=True)
passage_embedding = model.encode(question_summary_en_list, convert_to_tensor=True)
# Use Cosine Similarity
cos_score = util.cos_sim(query_embedding, passage_embedding)
# Normalize
cos_score_percent = cosine_similarity_to_percent_general(cos_score)
cos_score_percent_list = cos_score_percent.tolist()[0]
""" 2. 계산된 데이터 중 유사도 상위 3개 데이터 추출 """
similarity_list = [{'similarity_percent': 0}, {'similarity_percent': 0}, {'similarity_percent': 0}]
for doc, score in zip(data, cos_score_percent_list):
doc['similarity_percent'] = score
sim_list = [d['similarity_percent'] for d in similarity_list]
if score > min(sim_list):
idx_min = sim_list.index(min(sim_list))
similarity_list[idx_min] = doc
""" 3. 유사도 점수가 기준 점수(SIMILARITY_CRITERION_POINT) 이하인 데이터 삭제 """
# result_similarity_list = []
# for doc in similarity_list:
# if doc['similarity_percent'] > SIMILARITY_CRITERION_PERCENT:
# result_similarity_list.append(doc)
# 유사도 상위 3개의 데이터 출력
# print(result_similarity_list)
""" 결과가 3개 미만일 경우, 빈 리스트를 Spring Boot로 리턴"""
if len(similarity_list) < 3:
return []
""" 요약된 질문과 답변을 DTO로 담아서 리턴(Spring Boot로 전달) """
# List of DTOs
data_list = []
for i in similarity_list:
dict_ = dict()
dict_['question_summary'] = i.get('question_summary')
dict_['answer'] = i.get('answer')
dict_['similarity_percent'] = round(i.get('similarity_percent'), 2) # Rounded to 2 decimal places
data_list.append(dict_)
print(dict_)
# Sort the data_list by 'similarity_percent' in descending order
data_list = sorted(data_list, key=lambda x: x['similarity_percent'], reverse=True)
return data_list
if __name__ == '__main__':
app.run(debug=True)
requirements.txt
boto3~=1.28.16
Flask~=2.3.2
pymongo~=4.4.1
sentence-transformers~=2.2.2
3. 문제 사항
- EC2 리소스 낭비
- 메인으로 개발된 Spring Boot 서버와 달리, Flask 서버의 경우 위에서 챗봇 서비스 중 사용자가 질문을 할 때만 사용이 되며, 그 외에는 사용되지 않는 서비스이다. 사용하지 않을 때도 지속해서 실행되고 항상 사용 가능한 서버 또는 서버 블록을 구입하는 것은 리소스 낭비일 수 있다.
- 따라서, 비록 챗봇이 메인 기능이지만, Flask 서버를 5000 포트로 24시간 내내 EC2 인스턴스에 실행시키는 것은 리소스 낭비를 유발한다.
- Docker image 용량
- 아래는 `docker images` 명령을 통해 나온 결과인데, flask 프로젝트의 이미지 용량이 Spring Boot에 비해 훨씬 큰 것을 알 수 있다.
- 코드의 line 개수는 아래와 같이, Spring Boot 프로젝트(테스트 코드 제외)가 flask 프로젝트에 비해 약 10배 이상이 작성되어 있음에도 불구하고, flask 프로젝트의 이미지 용량이 Spring Boot에 비해 훨씬 큰 것을 알 수 있다.
- 이는 EC2의 Volume을 추가해야 하는 상황을 유발할 수 있다.
4. 컨테이너 이미지를 사용하여 AWS Lambda 배포
https://gallery.ecr.aws/lambda/python
- 따라서, 서버리스 컴퓨팅 서비스인 AWS Lambda를 사용하기로 하였다.
- 또한, 2020년부터 AWS Lambda는 컨테이너 이미지로 함수를 패키징하고 배포할 수 있는 기능을 제공하므로, AWS ECR과 연동해서 사용하면 버전 관리가 가능하다.
4-1. 코드 수정
Dockerfile
AWS] 컨테이너 이미지로 Python Lambda 함수 배포
위 링크를 참고하여 수정하였다.
주의] 마지막 줄에서, app.py에 lambda_handler 라는 명칭의 함수가 존재해야 한다.
# Use public ECR provided Python Runtime for AWS Lambda
FROM public.ecr.aws/lambda/python:3.9
# Set the working directory
WORKDIR ${LAMBDA_TASK_ROOT}
# Copy requirements.txt
COPY requirements.txt .
# Install the specified packages
RUN pip install -r requirements.txt
# Copy function code
COPY app.py .
COPY config.py .
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "app.lambda_handler" ]
app.py
이제 Flask 서버를 사용할 것이 아니므로, Flask 코드를 AWS Lambda 형식으로 수정하였다.
import boto3 # The AWS SDK for Python
from pymongo import MongoClient
from sentence_transformers import SentenceTransformer, util
import config
import os
# Declare a constant variable
TARGET_LANGUAGE_CODE = 'en'
SOURCE_LANGUAGE_CODE = 'ko'
# Similarity Criterion Percent
SIMILARITY_CRITERION_PERCENT = 10
def get_mongo_client():
username = config.MONGODB_USERNAME
password = config.MONGODB_PASSWORD
host = config.MONGODB_HOST
port = config.MONGODB_PORT
# Create a MongoDB connection URI
mongo_uri = f'mongodb://{username}:{password}@{host}:{port}/'
# Create the MongoDB client and return it
return MongoClient(mongo_uri)
def cosine_similarity_to_percent_general(cosine_similarity):
normalized_value = (cosine_similarity + 1) / 2
return normalized_value * 100
def lambda_handler(event, context):
os.environ['TRANSFORMERS_CACHE'] = "/tmp"
# Configure AWS Translate client
translate = boto3.client(service_name='translate',
aws_access_key_id=config.AWS_ACCESS_KEY_ID,
aws_secret_access_key=config.AWS_SECRET_ACCESS_KEY,
region_name=config.AWS_SEOUL_REGION)
mentor_nickname = event['mentor_nickname']
mentee_nickname = event['mentee_nickname']
question_origin = event['question_origin']
question_summary = event['question_summary']
""" 받아온 데이터 중, 세 줄 요약된 질문을 AWS Translate API를 통해 영어로 번역 """
translation_response = translate.translate_text(Text=question_summary, SourceLanguageCode=SOURCE_LANGUAGE_CODE,
TargetLanguageCode=TARGET_LANGUAGE_CODE)
""" Extract the translated text from the response """
translated_summary_text_en = translation_response['TranslatedText']
""" Connect MongoDB """
mongo_client = get_mongo_client()
menjil_db = mongo_client['menjil']
qa_list_collection = menjil_db['qa_list']
"""qa_list collection에 접근해서, Spring Boot에서 받아온 정보(멘토 닉네임, 멘티 닉네임, 원본 질문, 세 줄 요약된 질문)와 영어 번역본을 먼저 저장"""
document = {
# 마지막에 붙는 '\n' 제거
'mentee_nickname': mentee_nickname,
'mentor_nickname': mentor_nickname,
'question_origin': question_origin[:-1] if question_origin.endswith('\n') else question_origin,
'question_summary': question_summary[:-1] if question_summary.endswith('\n') else question_summary,
'question_summary_en': translated_summary_text_en[:-1] if translated_summary_text_en.endswith('\n')
else translated_summary_text_en,
'answer': None
}
insert = qa_list_collection.insert_one(document) # save a document
""" 멘토가 답변한 내역이 있는 문답 데이터를 모두 불러온다 """
filter_ = {
'mentor_nickname': mentor_nickname,
'answer': {'$exists': True, '$ne': None}
}
projection_ = {
'mentee_nickname': False,
'mentor_nickname': False,
'question_origin': False
}
# Retrieve the documents and store them in the data(list)
data = list(qa_list_collection.find(filter_, projection_))
print('data: ', data)
""" 문장 유사도 검증 """
""" 1. 유사도 검사"""
question_summary_en_list = [doc['question_summary_en'] for doc in data]
# for idx, qe in enumerate(question_summary_en_list):
# print(f'질문{idx + 1}: {qe}')
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2', cache_folder='/tmp')
query_embedding = model.encode(translated_summary_text_en, convert_to_tensor=True)
passage_embedding = model.encode(question_summary_en_list, convert_to_tensor=True)
# Use Cosine Similarity
cos_score = util.cos_sim(query_embedding, passage_embedding)
# Normalize
cos_score_percent = cosine_similarity_to_percent_general(cos_score)
cos_score_percent_list = cos_score_percent.tolist()[0]
""" 2. 계산된 데이터 중 유사도 상위 3개 데이터 추출 """
similarity_list = [{'similarity_percent': 0}, {'similarity_percent': 0}, {'similarity_percent': 0}]
for doc, score in zip(data, cos_score_percent_list):
doc['similarity_percent'] = score
sim_list = [d['similarity_percent'] for d in similarity_list]
if score > min(sim_list):
idx_min = sim_list.index(min(sim_list))
similarity_list[idx_min] = doc
""" 3. 유사도 점수가 기준 점수(SIMILARITY_CRITERION_POINT) 이하인 데이터 삭제 """
# result_similarity_list = []
# for doc in similarity_list:
# if doc['similarity_percent'] > SIMILARITY_CRITERION_PERCENT:
# result_similarity_list.append(doc)
# 유사도 상위 3개의 데이터 출력
# print(result_similarity_list)
""" 결과가 3개 미만일 경우, 빈 리스트를 Spring Boot로 리턴"""
if len(similarity_list) < 3:
return []
""" 요약된 질문과 답변을 DTO로 담아서 리턴(Spring Boot로 전달) """
# List of DTOs
data_list = []
for i in similarity_list:
dict_ = dict()
dict_['question_summary'] = i.get('question_summary')
dict_['answer'] = i.get('answer')
dict_['similarity_percent'] = round(i.get('similarity_percent'), 2) # Rounded to 2 decimal places
data_list.append(dict_)
print(dict_)
# Sort the data_list by 'similarity_percent' in descending order
data_list = sorted(data_list, key=lambda x: x['similarity_percent'], reverse=True)
return data_list
requirements.txt
주의] sentence-transformers==2.2.2만 넣으면, Lambda에서 오류가 발생한다.
StackoverFlow에서 검색을 해보니, "AWS Lambda currently doesn't support GPU-based operations directly, so any library or framework that requires direct GPU support (like some parts of PyTorch when it tries to load CUDA libraries) might fail." 라고 말해서,
CPU Only version of pytorch를 설치하기 위해 https://download.pytorch. ... 를 추가해야 한다.
pymongo~=4.4.1
numpy~=1.25.2
https://download.pytorch.org/whl/cpu/torch-1.11.0%2Bcpu-cp39-cp39-linux_x86_64.whl
sentence-transformers==2.2.2
그 외 오류 사항: 주로 AWS Lambda에서 ECR 이미지 실행 시 발생하였으며, 모두 Sentence Transformer 라이브러리 관련한 것이었다.
CloudWatch 로그에서 확인된, 오류 내용
1. There was a problem when trying to write in your cache folder (/home/sbx_user1051/.cache/huggingface/hub). You should set the environment variable TRANSFORMERS_CACHE to a writable directory.
Stackoverflow] How to change huggingface transformers default cache directory
해결] 아래 코드를 추가한다.
주의] 이때, 경로를 내 마음대로 지정하면 안 된다. AWS Lambda에서는 /tmp 영역에 임시 파일 시스템을 제공하며, 고정 크기는 512MB이다. 따라서, /tmp 영역 안으로 경로를 지정해야 한다!
( /tmp 영역은 실행 환경의 수명 동안 보존되며, 호출 사이의 데이터에 대한 임시 캐시를 제공한다. 새 실행 환경이 생성될 때마다 이 영역은 삭제된다. )
import os
os.environ["TRANSFORMERS_CACHE"] = "/tmp"
2. [ERROR] OSError: [Errno 30] Read-only file system: '/home/sbx_user1051' Traceback (most recent call last): File "/var/task/app.py", line 91, in lambda_handler model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
해결] cache_folder를 코드에 추가하였음.
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2', cache_folder='/tmp')
3. [ERROR] Runtime.UserCodeSyntaxError: Syntax error in module 'app': invalid syntax (config.py, line 3)
AWS Lambda Runtime.UserCodeSyntaxError: Syntax error in module 'salesAnalysisReport': invalid syntax
해결] Boto3에서는, single quote를 사용해야 한다. double quote를 사용해서 오류가 난 것이었음
4-2. IAM user 생성
4-3에서, GitHub Action 사용 시에 AWS IAM user의 정보가 필요하므로, IAM user를 생성하였다.
- AmazonEC2ContainerRegistryFullAccess
생성 이후, IAM user > Create Access Key 를 통해, Access Key, Secret Access Key 정보가 담긴 csv 파일을 저장한다.
4-3. AWS ECR 생성 및, GitHub Action을 사용한 CD 구성
주의] ECR 생성 시, 반드시 Private Repository를 생성해야 한다!!
Public Repository로 생성했는데, 이후 AWS Lambda에서 리포지토리가 검색이 되지 않아서 한참 헤맸다..
생성 이후 우측 상단에 "View push commands" 를 누르면 아래 사진과 같은 command를 볼 수 있는데,
- AWS CLI 설치 필요
- 코드에서 변경 사항이 발생할 때 마다 매번 명령어 입력
위 두 가지 번거로운 사항이 존재해서, GitHub Action으로 Deploy를 실행하기로 하였다.
app.yml
ECR_REPOSITORY의 경우 Repository 명칭을 작성한다. e.g) lambda-test
name: Deploy image To AWS ECR
on:
push:
branches: [ "main" ]
permissions:
contents: read
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-2
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
with:
mask-password: 'true'
- name: Build, tag, and push docker image to Amazon ECR
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
ECR_REPOSITORY: ${{ secrets.FLASK_ECR_REPO }}
IMAGE_TAG: ${{ github.sha }}
run: |
touch ./config.py
echo "${{secrets.APPLICATION_CONFIG}}" > ./config.py
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
실행 결과
위의 app.yml 코드가 정상적으로 실행되면, ECR Repository에, 아래와 같이 image가 등록이 된다.
4-4. AWS Lambda 함수 생성
Browse images를 클릭하면, 4-3에서 생성한 private repository를 확인할 수 있다.
public repository는 확인 불가능.
다음으로, 아래에서 사용하기 위한 IAM Roles을 생성한다.
설정한 권한 역시 사진 참고
Lambda 설정
정상적으로 생성되었다면, 다음 동작들을 수행한다.
1. Memory -> 512 MB, Timeout -> 1m 30s 로 변경
2. Json 데이터를 내 요청 형식에 맞도록 작성한뒤, Test 수행
3. 성공 시 아래와 같이 succeeded 메시지가 뜬다. 만약 실패하였다면, logs로 가서 원인을 확인 후 고친다.
4-5. API Gateway 생성 및 Lambda와 연결
1. API Gateway 생성
2. 리소스를 생성하고, 메서드를 생성한다. 나는 JSON 데이터를 body에 담아 전달하므로, POST 요청을 사용한다.
3. 정상적으로 동작하는지 test를 수행한다.
Request Body에 json 데이터를 입력하였다.
4. 위에서 테스트가 성공하였다면, Deploy API를 눌러 배포한다.
stage name은 prod, dev 등 마음대로 작성한다.
5. Invoke URL + 내가 작성한 Resources 경로를 추가하여, Postman으로 테스트 수행
정상적으로 응답이 오는 것을 확인할 수 있다.
5. 결론
- AWS ECR + Lambda + Api gateway를 사용하여, 기존 EC2 인스턴스의 부하를 줄일 수 있었다고 생각한다.
- AWS Lambda는 도커 이미지의 경우 10GB 용량 제한이 있으므로 추후 여러 머신러닝 라이브러리를 사용할 일이 있다면, AWS Sagemaker의 사용을 고려해볼 것이다.
- 현재 하나의 AWS Lambda에서 AWS Translate API, MonogoDB에 document 저장, 유사도 검증, 결과 응답 이 4가지의 기능을 수행하고 있는데, 아래와 같이 Lambda를 여러 개를 사용하여 기능을 분리한다면, 조금 더 안정적인 서비스가 되지 않을까 생각한다.
- AWS Translate API
- MonogoDB에 document 저장
- 유사도 검증 및 결과 응답
- 혹은 AWS Translate API, MonogoDB에 document 저장하는 두 절차는 Spring Boot에서 처리하고, 유사도 검증 및 결과 응답만 AWS Lambda에서 처리하도록 한다.
6. 더 나아가기
1. AWS에서, EC2 인스턴스의 상태를 확인이 가능하다면, Flask 서버를 띄웠을 때와 안 띄웠을 때 얼마나 차이가 나는지 확인이 가능한지.
2. ecr에 이미지 업로드 이후, 람다에서 직접 deploy를 수동으로 수행하고 있는데, 람다에 deploy 및 test도 github action에서 자동화할 수 있을까
'멘질멘질] 2023 졸업 프로젝트' 카테고리의 다른 글
| Spring Boot] API 문서의 신뢰도를 높이기 위한 Spring Rest Docs 도입 (0) | 2024.01.22 |
|---|---|
| Spring Boot] STOMP 프로토콜 (0) | 2023.09.01 |
| Junit5] @CreatedDate NullPointer Exception (0) | 2023.07.22 |
| Ubuntu] Docker 용량 줄이기 (0) | 2023.06.25 |
| Ubuntu] Next.js Dockerfile 경량화(Optimize) (0) | 2023.06.22 |